Latin Hypercube Sampling
What is LHS?
Latin hypercube sampling aims to bring the best of both worlds: the unbiased random sampling of monte carlo simulation; and the even coverage of a grid search over the decision space. It does this by ensuring values for all variables are as uncorrelated and widely varying as possible (over the range of permitted values).
Why do I need one?
The background to this is that I have been working on improving the convergence of an optimisation package that uses genetic algorithms. Having a good distribution of “genes”, or decisions within the initial population is key to allowing a GA to effectively explore the decision space. The ga() function within the GA package in R allows for a suggestions argument, which takes a matrix of decision values and places them within the starting population. Initially I wrote one function to create evenly spaced sequences for every decision between the lower and upper bound of allowable values, from which I enumerated all possible combinations using expand.grid(). I then wrote another function to take a model object and a user-defined population size and automatically work out the nearest population count that allowed for even sampling over the model’s decision bounds.
For models with large numbers of decisions the potential number of combinations is enormous. This is true even if you only select the upper and lower bound per decision. Already with 30 independent decisions with two possible values the number of combinations is 2^30 = 10,737,41,824, 10 times more than the number of stars in the average galaxy. Combinatorial algorithms are the worst type for growth in complexity (\(O(n!)\)). I needed a way of randomly sampling from the decisions but in a way that ensured the starting population had lots of diversity. This is the exact use case for LHS.
Practical examples
Let’s assume we have three decisions, where:
- decision a can be between 1 and 3,
- decision b can be TRUE or FALSE, and
- decision c can be red, green, blue or black
There are \(3 * 2 * 4 = 24\) possible unique combinations of these decisions (if a can only take on integer values). An individual in the starting population of a genetic algorithm would be of the form, 1_TRUE_red, for instance.
Let’s assume we would like only 12 individuals from the 24 potential unique combinations, but we still want good representation of all/most possible decisions. Using the lhs library from R, we first create 12 random uniform distributions between 0 and 1 for each of the three decisions, a, b and c.
library(lhs)
library(dplyr)
library(purrr)
# Test data
a <- 1:3
b <- c(TRUE, FALSE)
c <- c("red", "green", "blue", "black")
all_decisions <- rbind(list(a,b,c))
sample <- as.data.frame(randomLHS(12, 3))
names(sample) <- c("a", "b", "c")
# Uniform random values between 0 and 1
sample## a b c
## 1 0.2298605 0.57586455 0.15879497
## 2 0.6123669 0.93655235 0.52807091
## 3 0.1405182 0.86291310 0.05353759
## 4 0.6784085 0.04476613 0.39006544
## 5 0.0777695 0.28693076 0.99092477
## 6 0.9939800 0.20343707 0.27813226
## 7 0.5170630 0.47209350 0.78766487
## 8 0.8783984 0.09234600 0.49824405
## 9 0.4196785 0.83133533 0.69800889
## 10 0.3825627 0.58463731 0.66272508
## 11 0.7590192 0.39640356 0.23725054
## 12 0.2929710 0.72958857 0.86157621Next we map the 0-1 distributions onto the real distributions of a, b and c. For instance, c has four possible values so the distribution should be 1-4. We also convert the values to factors in order to label them properly.
# Random choices for each decision with distributions based on a, b and c
choices <- map2(sample, all_decisions,
~cut(.x, length(.y), labels = .y)) %>%
bind_rows()
choices## # A tibble: 12 x 3
## a b c
## <fct> <fct> <fct>
## 1 1 FALSE red
## 2 2 FALSE blue
## 3 1 FALSE red
## 4 2 TRUE green
## 5 1 TRUE black
## 6 3 TRUE red
## 7 2 TRUE black
## 8 3 TRUE green
## 9 2 FALSE blue
## 10 1 FALSE blue
## 11 3 TRUE red
## 12 1 FALSE blackFor convenience we can bring this into a single function like so.
lhs_sample <- function(decisions, n){
stopifnot(is.list(decisions))
len_decisions <- length(decisions)
samples <- lhs::randomLHS(n, len_decisions) %>%
as.data.frame()
names(samples) <- names(decisions)
choices <- purrr::map2(samples, decisions,
~cut(.x, length(.y), labels = .y))
bind_rows(choices)
}
lhs_sample(list(cars = rownames(mtcars), species = unique(iris$Species), letter = LETTERS[24:26]), n = 10)## # A tibble: 10 x 3
## cars species letter
## <fct> <fct> <fct>
## 1 Volvo 142E setosa Y
## 2 Mazda RX4 versicolor Z
## 3 Hornet Sportabout virginica X
## 4 Camaro Z28 setosa Z
## 5 Merc 450SLC setosa X
## 6 Chrysler Imperial versicolor Y
## 7 Toyota Corona virginica Z
## 8 Porsche 914-2 virginica X
## 9 Merc 240D setosa Z
## 10 Merc 450SE versicolor YContinuous distributions
The above example was for sampling from distributions where allowable values were either factors or whole integers. For continuous numerical distributions we can use the following.
library(tidyr)
a_continuous <- all_decisions[[1]]
choices_continuous <- qunif(sample$a, min = min(a_continuous), max = max(a_continuous))
choices_continuous## [1] 1.459721 2.224734 1.281036 2.356817 1.155539 2.987960 2.034126 2.756797
## [9] 1.839357 1.765125 2.518038 1.585942Testing coverage
In theory, each sample should be orthogonal, or independent, of each other sample to the greatest possible extent. Another way of putting it is that there should neither be any one value overrepresented or under-represented in the sample set. Let’s test this in practice:
library(ggplot2)
big_sample <- lhs_sample(decisions = list(a = a,b = b,c = c), n = 1000)
ggplot(big_sample, aes(x = c, fill = c)) +
geom_bar() +
scale_fill_manual(values = c("red", "green", "blue", "black")) +
labs(title = "For a single decision, each value has been sampled equally")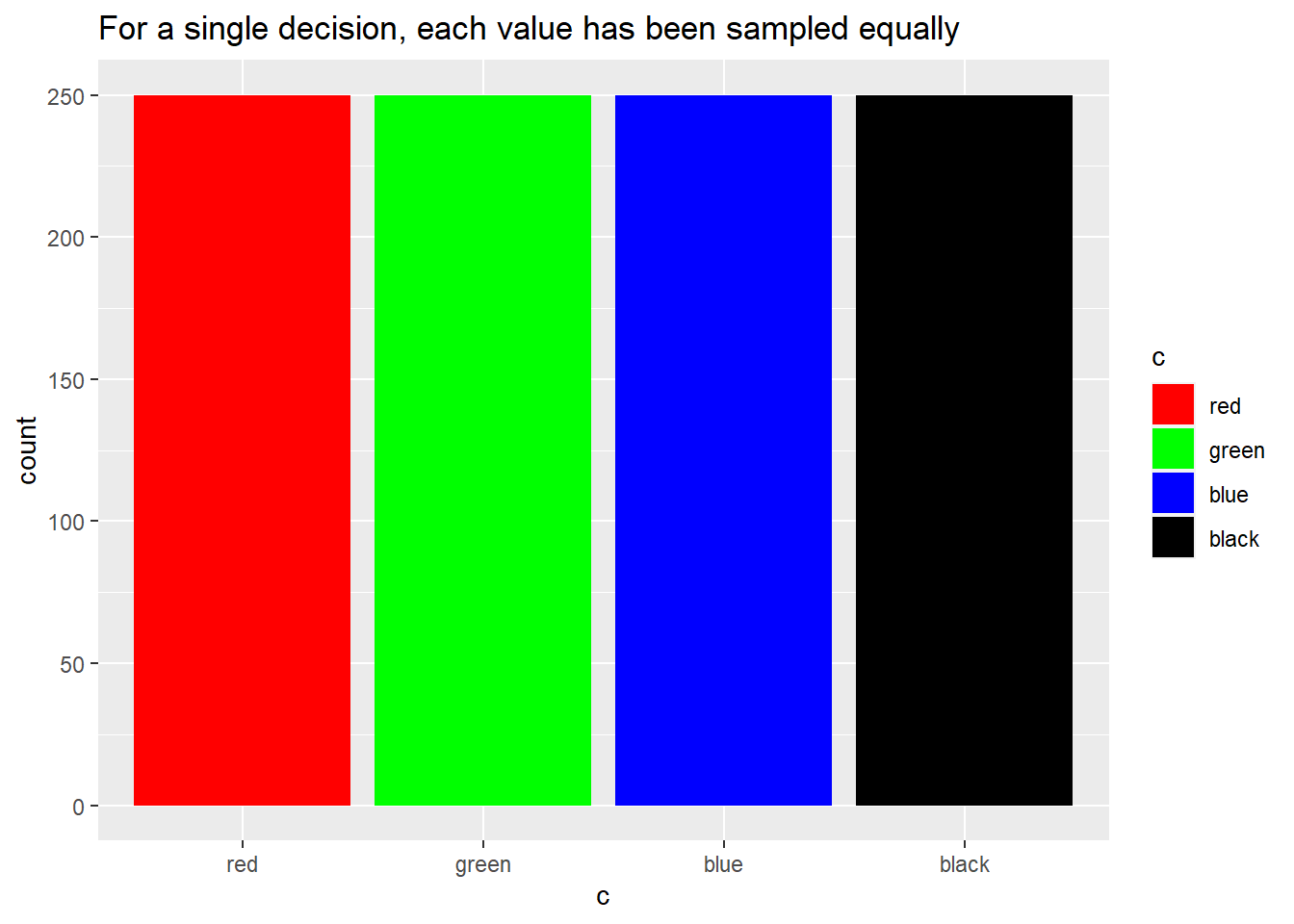
ggplot(big_sample, aes(x = a, y = b, colour = c)) +
geom_jitter() +
scale_colour_manual(values = c("red", "green", "blue", "black")) +
labs(title = "Every value combination across all decisions has also been sampled equally")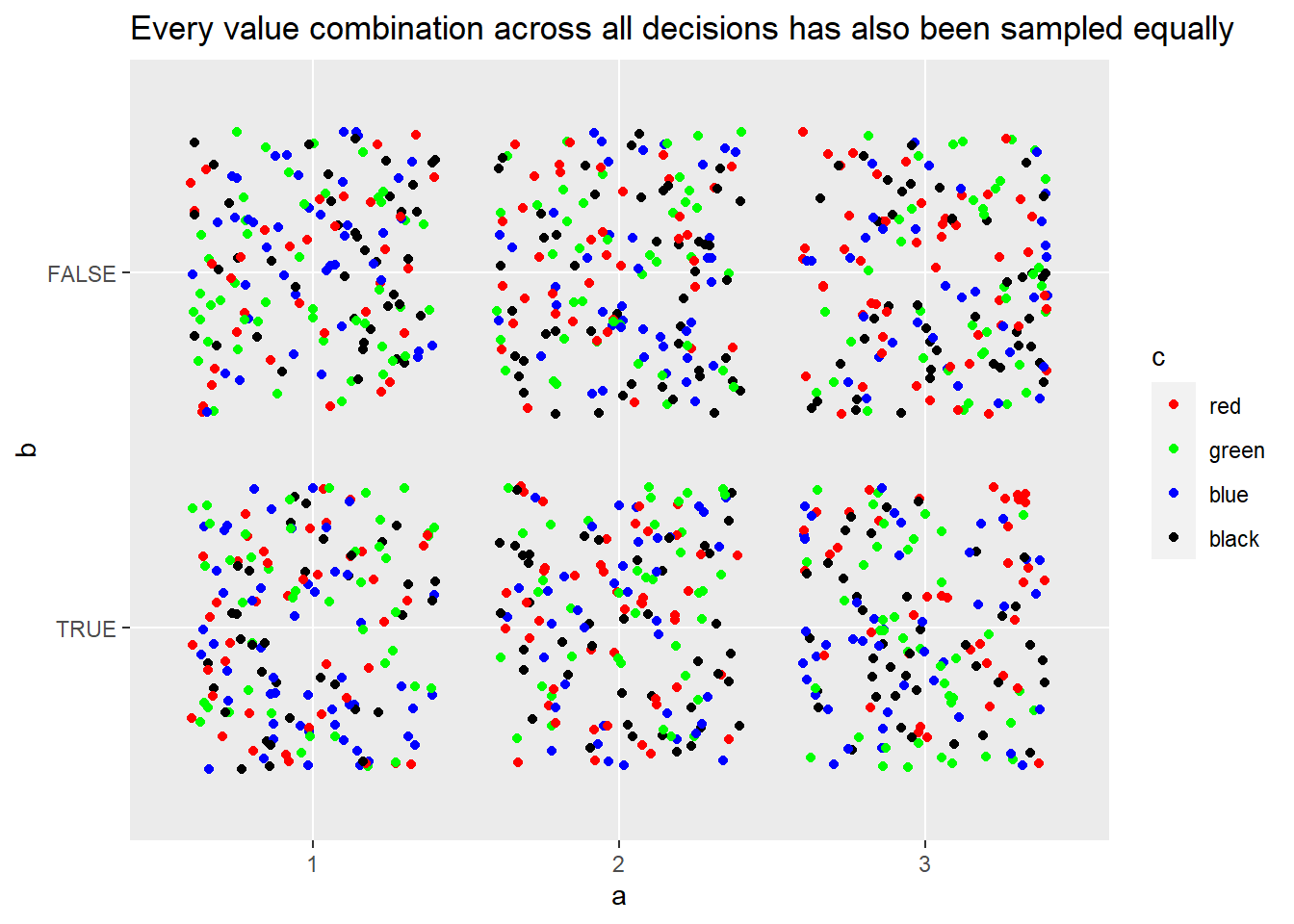
Richard Davey
Group Leader, Data & Decision Science
My interests include earth science, numerical modelling and problem solving through optimisation.